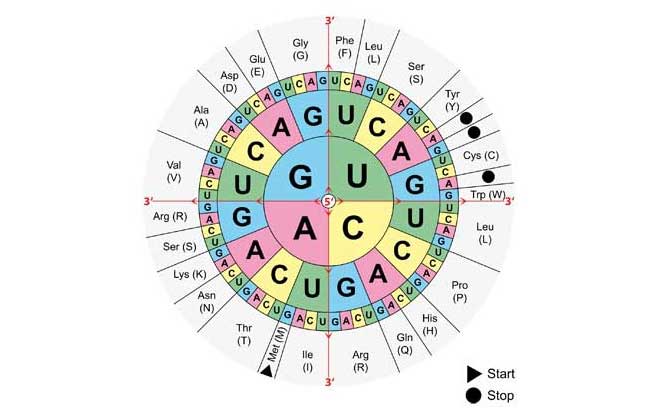
O design biológico está assentado sobre a natureza instável da fisicalidade. Assim como nas nossas tecnologias, é necessário imunidade a esse ruído natural. A partir de sua concepção, um sistema informacional requer uma camada extra de informação para resistir a essas oscilações.
A Camada Extra: um Código de Segunda Ordem
Em canais de comunicação a instabilidade natural supracitada, o envelhecimento de componentes, as interferências eletromagnéticas, entre outros fatores, acabam afetando a informação fazendo com que os dados enviados sejam trocados ou perdidos. Entre as soluções de engenharia nós podemos encontrar os chamados códigos Hamming.

Os códigos Hamming são criados com bits de redundâncias intencionais acrescidos aos códigos comuns para garantir a integridade dos dados. O objetivo é criar um conjunto de bits de sobrepostos aos bits da mensagem, e relacionados com eles, de modo que um erro num único bit (de dados ou sobreposto) possa ser detectado e corrigido.
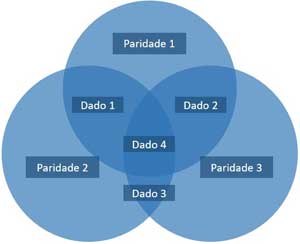
Apesar de ser possível muitas sobreposições, o formato Hamming (7,4) é o mais usado (onde são 7 bits sendo 4 de informação e 3 de “segurança” (paridade). [Exemplos]
Cada bit de paridade está sobreposto sobre 3 bits de dados e caso a soma deles seja par, a paridade será “0”, caso seja ímpar, será “1”. Por isso que é possível detectar e corrigir automaticamente um erro e apenas detectar (sem conseguir corrigir) até dois erros. Esta é a solução para sistemas de informação, mas e nos sistemas biológicos?
O Ápice dos Sistemas Cibernéticos
O design biológico é mais sofisticado que qualquer tecnologia humana e requer um sistema robusto contra ruídos, porque quanto mais funcionalidades e atividade, mais suscetibilidade (risco) em termos operacionais. Neste contexto, os códigos biológicos estabelecidos são extremamente confiáveis e podem ficar inalterados em escalas de tempo cosmológicas (é, na verdade, a estrutura mais durável conhecida).
Um padrão subjacente foi encontrado dentro do código genético que “sobrepõe” possíveis erros através de redundância e aminoácidos similares bioquimicamente próximos no espaço de codificação, minimizando o impacto de mutações e/ou erros de tradução. Quando uma mutação ocorre, o mesmo aminoácidos permanece ou um muito semelhante em propriedades fisicoquímicas assume sua posição. Assim o sistema se torna extremamente forte contra o ruído natural.
A questão é que existem várias propriedades envolvidas, e elas foram organizadas da melhor forma possível [1]:
Quando o valor de erro do código padrão é comparado com o menor valor de erro de qualquer código encontrado em uma pesquisa extensiva de espaço de parâmetro, os resultados são um pouco mais variáveis. Estimativas (…) indicam que o código padrão alcança uma otimização entre 96% e 100% em relação à melhor configuração de código possível. Se a nossa definição de restrições biossintéticas for uma boa aproximação da possível variação a partir da qual o código padrão emergiu, então ela parece estar próxima ou muito próxima de um ótimo global para a minimização de erros: o melhor de todos os códigos possíveis.
Seleção Adaptativa versus Design Inteligente
Em 2011 Jed C. Macosko e Amanda M. Smelser apresentaram um trabalho sobre o código padrão em um simpósio da Cornell University. O artigo deles comparava a origem do juste fino do código por inteligência com a origem por seleção adaptativa [2]:
Esta tabela foi chamada de um acidente congelado por Francis Crick, mas a evidência atual aponta para a otimização que minimiza os efeitos nocivos de mutações e erros de tradução, ao mesmo tempo em que maximiza a codificação de múltiplas mensagens em uma única sequência. Por exemplo, um artigo recente com o título em execução “O melhor de todos os códigos possíveis” concluiu que “evidência é clara” para a natureza otimizada do código padrão, e outro estudo descobriu que os sinais secundários difíceis de codificar são minimizados pelo código padrão”.
Não era a complexidade, mas a sofisticação que chamava a atenção: simplicidade e eficiência. Diziam eles:
“A Tabela Padrão de Códons (TPdC) é de forma alguma a parte mais complexa do mundo biológico. Pelo contrário, sua relativa simplicidade é a razão de ter sido examinada neste trabalho. (…) Se a otimização da TPdC situa-se entre ‘um em um milhão’ e ‘o melhor de todos os códigos possíveis’, como é provável que seja o caso, as hipóteses de necessidade ou acaso são cada vez mais insustentáveis e a inteligência externa torna-se a hipótese de trabalho mais promissora.”
Um Código para o Ritmos dos Processos Biológicos
Em 2014, já envolvido com o Design Inteligente, duas questões me intrigavam: o porquê da redundância do código genético e como era determinada a cadência (ritmo) da tradução de proteínas (importante para o enovelamento). Em um só artigo as duas questões foram respondidas [3]:
“A redundância códon (“degenerescência”) encontrada em regiões codificantes de proteínas de mRNA também prescreve Pausa de Tradução (PT). Quando combinado com os interpretadores adequados, múltiplos sentidos e funções são programados para a mesma sequência de ajuste de chaves configuráveis. Essa camada adicional de Informação Prescritiva Ontológica (IPO) propositadamente atrasa ou acelera o processo de tradução-decodificação dentro do ribossomo. As taxas de conversão variável ajudam a prescrever a dobragem funcional da proteína nascente. A redundância de códons no mapeamento de aminoácidos, por conseguinte, não é nada supérflua ou degenerada. A programação com redundância permite a dupla prescrição simultânea da “Pausa de Tradução” e atribuições de aminoácidos sem interferência.”
Vemos então que o “coração” que determina o ritmo dos sistemas biológicos começa a ser delineado desde o código padrão.
Um Outro Código Genético Paralelo

Um segundo código descoberto instrui a célula sobre como os genes são controlados. Esse código é escrito sobre o outro de tripletos e é por isso que permaneceu desconhecido por tanto tempo. Enquanto os bem conhecidos tripletos estão relacionado à sequência proteica, os duons estão relacionados ao controle do gene. Um comentário na Science diz:
Apesar da redundância no código genético, a escolha dos códons usados é altamente tendenciosa em algumas proteínas, indicando que restrições adicionais operam em certas regiões do genoma que codificam proteínas. Isso sugere que a preferência por códons específicos e, portanto, aminoácidos em regiões específicas da proteína, é frequentemente determinada por fatores não relacionados à estrutura ou função da proteína.
Sim, o termo “escolha” é usado como uma teleologia pura na Science. O segundo código, à parte ainda do padrão de minimização de erros e do ritmo de tradução citados anteriormente, é crítico de acordo com o pesquisador:
“O fato de que o código genético pode simultaneamente escrever dois tipos de informação significa que muitas mudanças no DNA que parecem alterar as sequências de proteínas podem realmente causar doenças ao interromper os programas de controle de genes ou até mesmo ambos os mecanismos simultaneamente”, disse Stamatoyannopoulos.
Origem “obscura”
O primeiro artigo citado aqui [1], que pode ser literalmente traduzido como “a fixação precoce de um código genético ótimo”, deixa margem de interpretação de que o código deve ser estabelecido antes de tudo e, pela analogia “congelada”, de uma só vez. O artigo, como todos da área, tenta responder evolutivamente a questão:
As forças evolutivas que produziram o código genético canônico antes do último ancestral universal permanecem obscuras.
As variações ligeiras do código padrão não vão muito longe, como que restringidas pela dinâmica, indicando que não há caminhos evolutivos que prosperem distante do código padrão:
Todos os códigos genéticos fora do padrão conhecidos parecem ser secundariamente derivadas de pequenas modificações do código padrão.
O código genético poderia surgir mais simples e evoluir na direção do código padrão? Bom, nós sabemos que o código padrão está distribuído em mais de 40 moléculas independentes que participam do sistema de tradução. Uma verdadeira orquestra bem afinada. Penso que o ajuste fino, evidência explícita de design, seja a melhor inferência.
Observação: A verdade é que apenas Dave Abel e D’Onofrio, do artigo sobre velocidade a partir do código, e o Dr. Macosko e a Dra. Smelser, que inspiraram este texto, são favoráveis ao Design Inteligente, todos os outros estão obstinadamente tentando demonstrar um “acidente congelado” ou a mediocridade do código padrão.
| Sobre o Código | ||||
| Predição | Realidade | |||
| “Não há razão para acreditar… que o presente código é o melhor possível, e ele poderia ter facilmente alcançado sua presente forma por uma sequência de felizes acidentes.” | “[o código genético] exibe algo como, ou muito próximo a, uma otimização global para minimização de erro: o melhor de todos os códigos possíveis.” | |||
| FHC. Crick (1968) [4] | SJ Freeland et al (1999) [1] | |||
[1] SJ Freeland et al. Early fixation of an optimal genetic code. 1999. [2] Jed C. Macosko* e Amanda M. Smelser em An Ode to the Code: Evidence for Fine-Tuning in the Standard Codon Table. Proceedings of the Symposium. Cornell University, USA, 31 May – 3 June 2011 [3] David J. D’Onofrio and David L. Abel. Redundancy of the genetic code enables translational pausing. 2014. [4] FHC. Crick. The origin of the genetic code. 1968.
Faça um comentário